Parallel Random Access Memory (PRAM)
“Living in a technological world where computation is not just about solving problems and finding optimal algorithms behind the scenes, but also about how quickly the problems are solved, is where high-performance computing (HPC) comes in!”

Most likely, you are here because you are a computer science (CS) major who is taking a class on algorithms or data structures. If you’re interested in computer science (CS) as a field of study or as a means to improve your career prospects in some other area, you should know that we’re living in the age of parallel computing, and that means you’ll need to be able to think in parallel when designing solutions to problems.
This is because the computing platforms we’ll be using in the future will all have multiple processing units that can manipulate data simultaneously. Therefore, we will start talking about the parallel thinking process involved in designing algorithms to solve issues in this course.
Let’s say sorting a set of N objects, where N may be quite large, is one of the first problems we shall study because it is one of the fundamental problems in computer science.
The complexity and performance of parallel algorithms may be better reasoned about if we have a firm grasp on the different kinds of parallel platforms that exist in practice, and how we can use an abstract theoretical parallel machine instead.
Let’s study about parallel algorithm model in random access memory and know-how can these processors can be connected.
INTRODUCTION
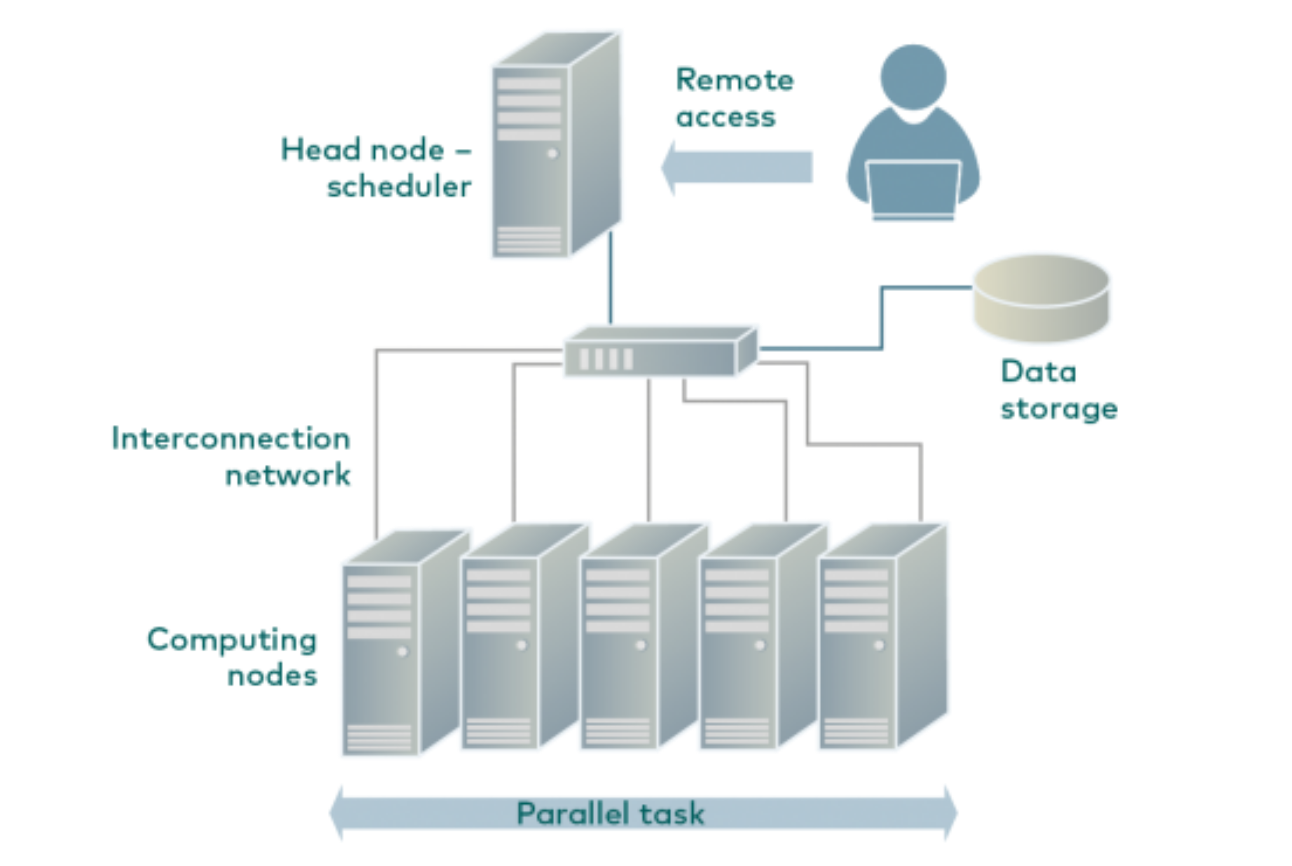
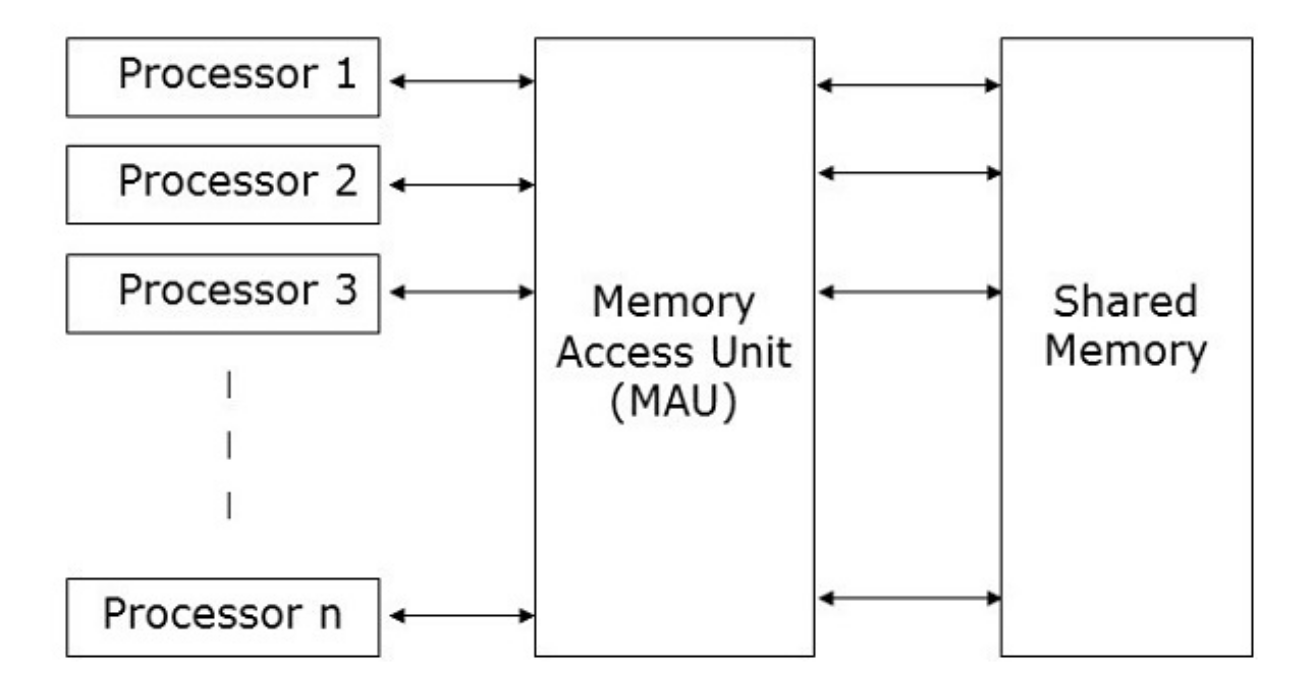
Most parallel algorithms consider a model called Parallel Random-Access Machines (PRAM). Here, a single block of memory is connected to several processors. A PRAM model includes a collection of processors of the same type.

A single memory unit is shared by all of the processors. The only means by which processors can communicate with one another is through shared memory. The single shared memory is connected to the processors by a memory access unit (MAU).
TYPES OF PARALLEL COMPUTERS AND PLATFORMS
The vast majority of personal computers sold to consumers prior to 2004, when the first dual-core processors for budget PCs were available, only had a single CPU (CPU). The first affordable dual-core processors hit the market in 2004, and they quickly became a standard in budget desktop computers (CPU). In 2004, the first dual-core CPUs became available for budget PCs, and they immediately gained widespread use (CPU). They were classic von Neumann computers, which executed programs line by line in the order in which they were given. Only a subset of these instructions may reach the RAM that is directly attached to the CPU, either to read data from it or to write values to it. The CPU can use this memory to store data. It has been theorized that the RAM computing style is used in these devices, as this is the method widely accepted to provide the best level of reliability. In this setup, a single CPU may access the device’s memory for reading and writing. Reading from memory is possible as well.
Now available in everything from laptops and desktop PCs to the newest generation of netbooks and mobile phones, dual-core CPUs are quickly becoming the norm in consumer electronics. This is because, in many cases, dual-core CPUs are more productive than single-core ones. A single chip with a central processing unit (CPU) and two ‘cores’ that are capable of executing instructions are increasingly represented by this term. The term “multicore” is commonly used to refer to specific types of central processing units since they are commonly found in high-end desktop workstations and servers (generally between 4 and 8). (CPUs). This trend toward ever-increasing core counts is likely here to stay for the foreseeable future, making a return to the days when computers had a single CPU impossible.
Although multi-core processors are becoming more common in individual computers, a more recent trend is to pool the processing capacity of numerous computers to address increasingly difficult computational and data-processing problems. This innovation follows the growing popularity of devices with many CPUs built into a single chassis. This trend is expected to continue growing over the next years. It is expected that this trend would maintain its upward momentum for the foreseeable future. Since the beginning of the 1980s up to the middle of the decade, an enormous number of high-priced computers with a plurality of processors have been produced in an effort to handle the most challenging computing issues that are presently facing the globe.
The practice of assembling clusters of commodity PCs began in earnest around the decade’s midpoint. By communicating with one another via a network, these individual PCs may simulate a supercomputer with many processors (which could be multicore themselves). A specific sort of computer cluster is commonly referred to as a “Beowulf cluster” when the word is used in common vernacular. The name “Beowulf” stems from the cluster itself, which was the first of its sort to be made and published. Major Internet software businesses like Google, Yahoo, and Microsoft employ massive data centers with thousands of computers to analyze vast quantities of data and answer search queries provided by millions of users. The facilities housing these data sets are situated in very safe areas. These facilities are also known as data farms. Multiple tasks are completed with the help of the data centers.

Those of us who are capable of creating parallel programs now have the option to use the processing capacity of computers situated in “the cloud,” also known as elsewhere on the Internet and away from our own physical location, as a result of a recent decision taken by Amazon Web Services. This move allowed us to take use of the processing capacity of machines residing in “the cloud.” This is made possible since the company has decided to lease out portions of its data centers to other companies at prices that are affordable for all of them.
The following is a list of the key sorts of parallel computing systems that are presently being employed on a size that is believed to be realistic as a direct result of this:
- Recent developments in the field of computing include, among other things, multicore processors with shared memory, clusters of computers that may be used in conjunction with one another, and massive data centers that are hosted in the cloud.
- In addition, several varieties of multiprocessor computers tailored to parallel processing were developed in the past. There were many different styles of computers available. There was a large selection of available computer setups. The scientific research conducted on these machines in the 1980s and 1990s serves as the basis for our explanation of the theoretical framework shown below, which is utilized to characterize models of parallel computing.
- This study was done in order to offer an explanation for the following theoretical framework, which is used to describe models of parallel computing. This study was conducted to shed light on the theoretical framework described below, which is used to define parallel computing model types.
THEORETICAL PARALLEL COMPUTING MODELS
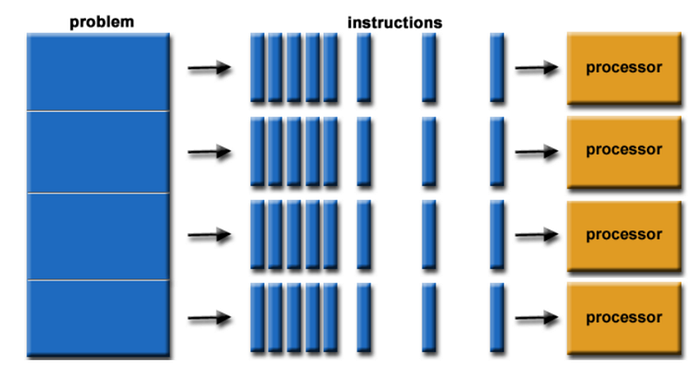
Our capacity to understand how computer systems function has been hampered by the proliferation of a wide variety of various kinds of computer systems. In the following discussion, for the sake of brevity, we shall refer to all conceivable processing units that are capable of executing instructions across the three primary kinds of platforms as “processors” (you will likely see this term being used differently in future hardware design or operating systems courses).
It is possible for none of the processors, all of the processors, part of the processors, or all of the processors to share the same memory (each has its own assigned memory). There is a potential that data can be sent across all of the CPUs, but there is also a chance that this is not the case. Because there are many different kinds of computer models, it is necessary to provide a structure that can be used for describing and talking about them. The computing paradigm that is being utilized will determine the degree to which a certain collection of algorithms may be able to speed up the execution of comparable work on a single sequential RAM machine.
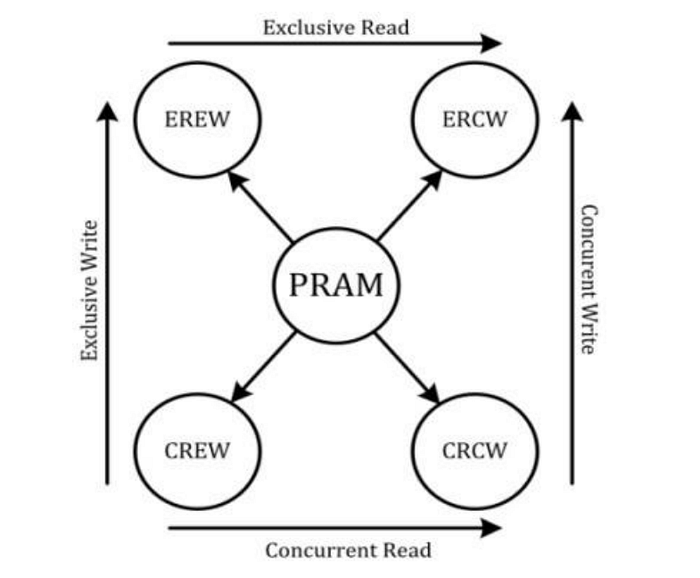
VERSIONS OF THE PRAM MODEL
- Exclusive Read and Exclusive Write (EREW). A memory value can only be read by a single processor at a time, and the same is true for writing a memory value: only one processor at a time can do so.
- Exclusive Read Concurrent Write (ERCW). In this instance, it is forbidden for two processors to read data from the same memory location at the same time. However, it is acceptable for both processors to write data to the same memory location simultaneously.
- Concurrent Read Exclusive Write (CREW). It is possible for multiple processors to read a data value at the same time, but only a single processor can write a memory value at any given time.
Here’s something to think about:
Do we need to worry about whether we have an EREW, CREW, or CRCW data access pattern if we are assuming a SIMD PRAM machine?
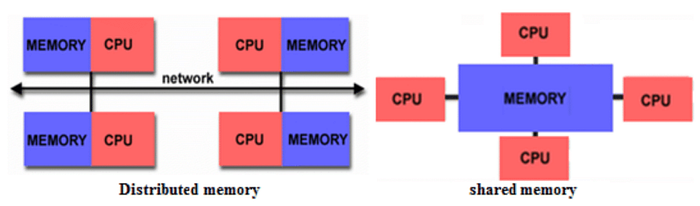
THE DISTRIBUTED MEMORY MODEL
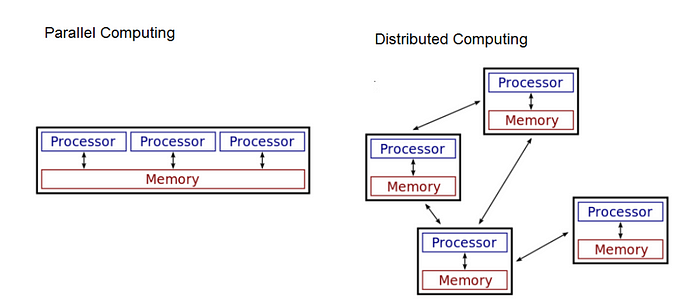
Compared to the shared-memory PRAM paradigm, the completely distributed model exists at the other end of the spectrum (figure). In this setup, each CPU has its own memory and relies on inter-CPU communication to share information. Data centers and clusters are included here. In the situation of distributed memory, Single Program, Multiple Data is a popular sort of execution model for programs (SPMD). In SPMD, each processor runs a program written as a task to be completed on some data. Each processor can either receive data from another processor to process or can use data that is already stored locally. Occasionally, it may be required for the programs to synchronize and share the information they have been working on.
There are many other hybrid parallel computer architectures where processors have both private memory and access to a common memory space.
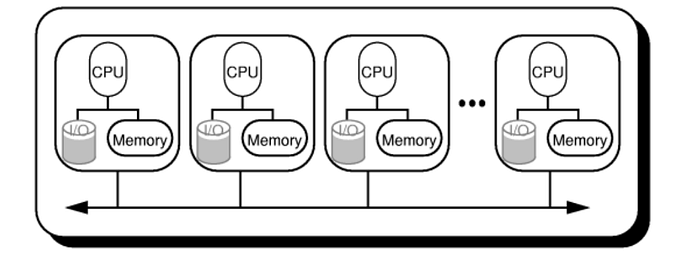
As a result of the diversity of parallel computing systems, there is a corresponding diversity of programming models. However, the theoretical PRAM model (MIMD assumed) with one of its three alternative memory access techniques is beneficial for thinking about parallel algorithms and reasoning about their efficiency. Therefore, we may create algorithms and estimate their performance, and then put those algorithms into practice on a variety of platforms with the help of a variety of related applications.
ARRANGEMENT OF PROCESSORS
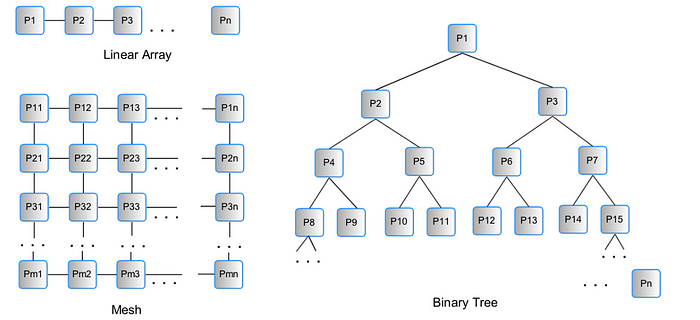
The PRAM idea will serve as the foundation for the building of our parallel method. We may construct a prospective parallel solution by thinking about the original sequential solution and looking for places where operations can be conducted in parallel. This will allow us to create a solution that is more efficient. Next, we will determine whether the algorithm accesses the data using EREW, CREW, or CRCW. If it does, we will proceed. Either we may begin by taking the easy approach of assuming that we have an endless number of processors, or we can decide to keep the number of processors, n, constant from the beginning. It will be helpful to think about how the processors might talk to one another, which we can accomplish by envisioning them in a given arrangement. Specifically, it will be helpful to think about how the processors might talk to one another. A linear array (which can be enlarged to a ring by connecting P1 to Pn), a mesh, and a binary tree are depicted as the three simplest potential topologies in Figure 3. A linear array can be expanded to a ring by connecting P1 to Pn.
IMPLEMENTATION
Even though a combination of a central processing unit (CPU) and dynamic random-access memory (DRAM) does not allow concurrent access to a single bank (not even various addresses within the bank), PRAM algorithms cannot be parallelized (DRAM). In contrast, a CRCW method may be used to read from and write to the static random-access memory (SRAM) blocks within a field-programmable gate array (FPGA), allowing for a hardware implementation of a PRAM technique. To parallelize the procedure while using PRAM is not possible.
This is the acid test to see if PRAM or RAM algorithms have any practical use in the real world, as the structure of the actual computer may differ significantly from the structure of the abstract model. Because it is outside the scope of this tutorial, learning about the other software and hardware layers is not included. Publications, such as Vishkin’s (2011), demonstrate how the XMT paradigm may accommodate a PRAM-like abstraction. Furthermore, studies published in publications such as Caragea and Vishkin (2011) suggest that using a PRAM approach to address the maximum flow issue could result in considerable speedups when compared to the usage of the fastest serial program to tackle the same problem. In their research article, Ghanim, Vishkin, and Barua (2018) showed that PRAM algorithms, in their current form, may achieve competitive performance on XMT without any further effort being done to transform them into multi-threaded programs.
CONCLUSION
The term “parallel programming” is used to describe the practice of creating applications that use multiple processor cores to execute various tasks concurrently. In contrast, the goal of concurrent programming is to carry out several operations concurrently.
Popular programming languages today offer only rudimentary to robust support for concurrent programming and only limited to no support for parallel computing. Many programmers have little or no expertise in building parallel programs and little experience working with concurrency. However, parallel programming is more popular in specialized fields like computer graphics.
Commonly, coarse-grained parallelism may be attained with the help of concurrency support. Since then, coarse-grained techniques of parallelism have gained a lot of traction. Coarse grain parallelism can only be used with certain methods and workloads (such as those involving large weakly connected datasets).
New hardware support is needed if fine-grained MIMD parallelism is to be successful (to align with existing programming models). Sequential code executes quickly on existing hardware, but there might be a performance hit of thousands of instructions if several cores need to interact or synchronize. Numerous scenarios are possible at this point:
Replace a small number of complicated cores with a larger number of relatively basic cores.
The integration of a Field Programmable Gate Array (FPGA) on the same chip as a conventional multi-core processor. The conventional core can coordinate with the FPGA to perform fine-grained tasks.
Convergence between graphics processing units (GPUs) and central processing units (CPUs) is already occurring. The Single Instruction Multiple Threads (SIMT) feature, which is supported by GPUs, helps to fix the problem of the instruction streams diverging.
Cores optimized for a particular use case, either co-located with general-purpose processors or on a separate die. A larger collection of instructions, including implementations of frequently used logic, can be found in the hardware.
In the near future, we will have non-volatile memory such as 3D XPoint. As a result of changing the memory hierarchy, several performance trade-offs will be affected.